
NEPCTF2025-pwn
| 0 | 前言
今年的nep和往年比简单不少,但对我来说还是很有挑战的 QwQ
之前的半个月因为学iot和kernel导致我对二进制安全有点提不起兴趣,但是nep一下把我的状态打满了 :)
本次的成绩为4/5,差一点ak了
| 1 | 题目解析
0x00.Time
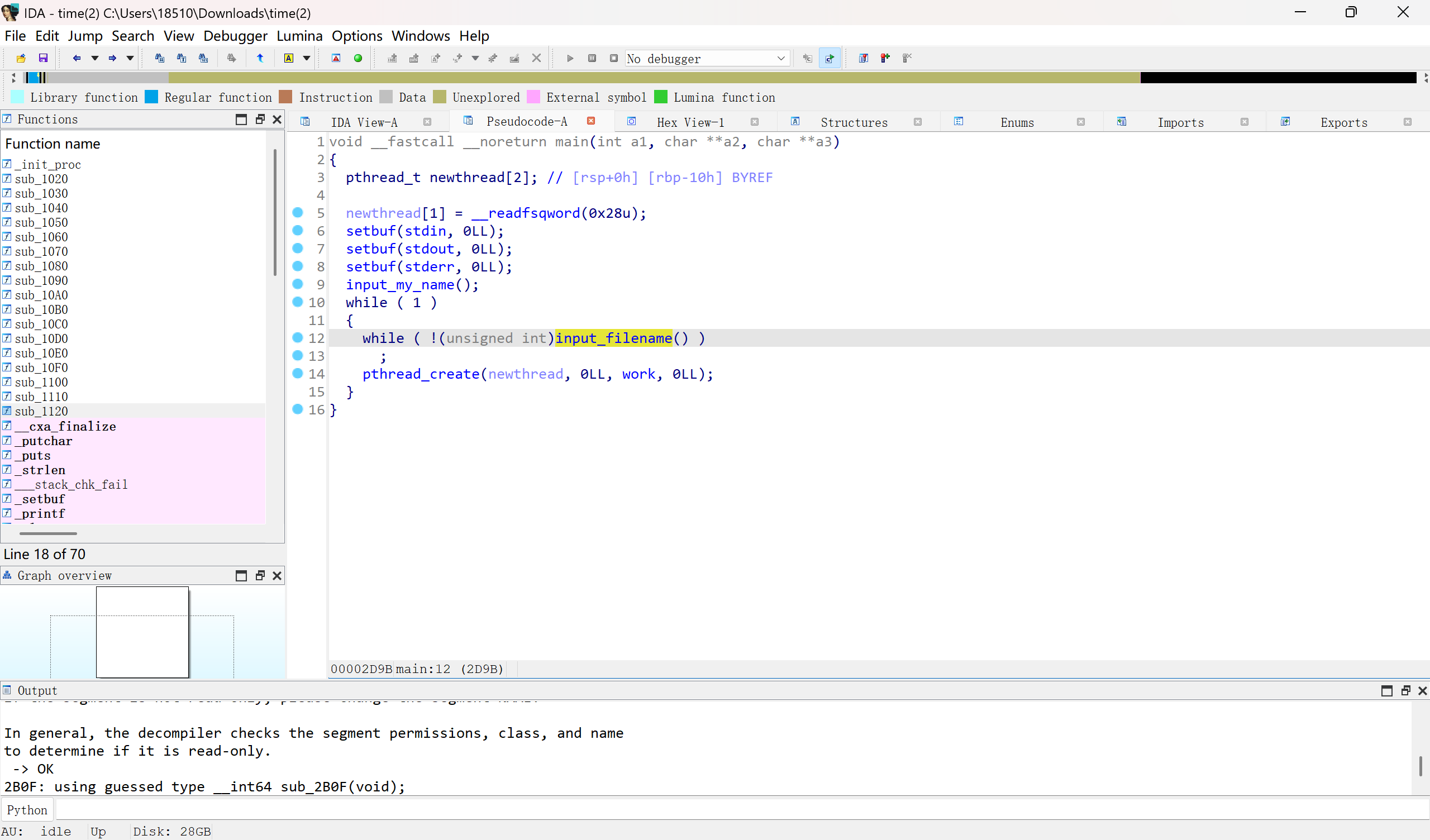
1 | unsigned __int64 input_my_name() |
1 | __int64 input_filename() |
向全局变量出入一个100字节的name,然后列出根目录下的文件
检查输入的文件名,如果是flag就要重新输入(注意此时flag被输入了filename)
然后开启一个子线程运行work函数
1 | unsigned __int64 __fastcall work(void *a1) |
先计算filename的md5,然后如果文件存在,就把文件读入内存,并打印name
很明显这里存在着非栈上格式化字符串漏洞,通过%p/%x可以将读入内存的文件内容dump出来
现在我们需要的是打开flag文件,可是input_filename有过滤
线程相关
线程与进程关系
进程(Process) 是资源的集合(有自己独立的内存空间、文件描述符、栈等)
线程(Thread) 是进程中的一个执行流(共享内存、文件描述符,但有自己栈、寄存器等)。
线程是”轻量级”的进程,多个线程共享一个进程的大部分资源。
线程竞争
线程竞争(race condition)是指多个线程同时访问共享资源,并试图对其进行读写操作时,由于访问时序不确定,导致程序执行结果不一致或错误的现象
通常产生于
- 多线程环境中共享资源未加锁(或锁不当)
- 写操作与写操作、写操作与读操作同时发生
- 时序不可控,调度由内核或调度器决定
本题中,work线程和main进程同时访问了filename,分别为读入与打开
同时由于work进行了一次md5计算,打开时刻会靠后
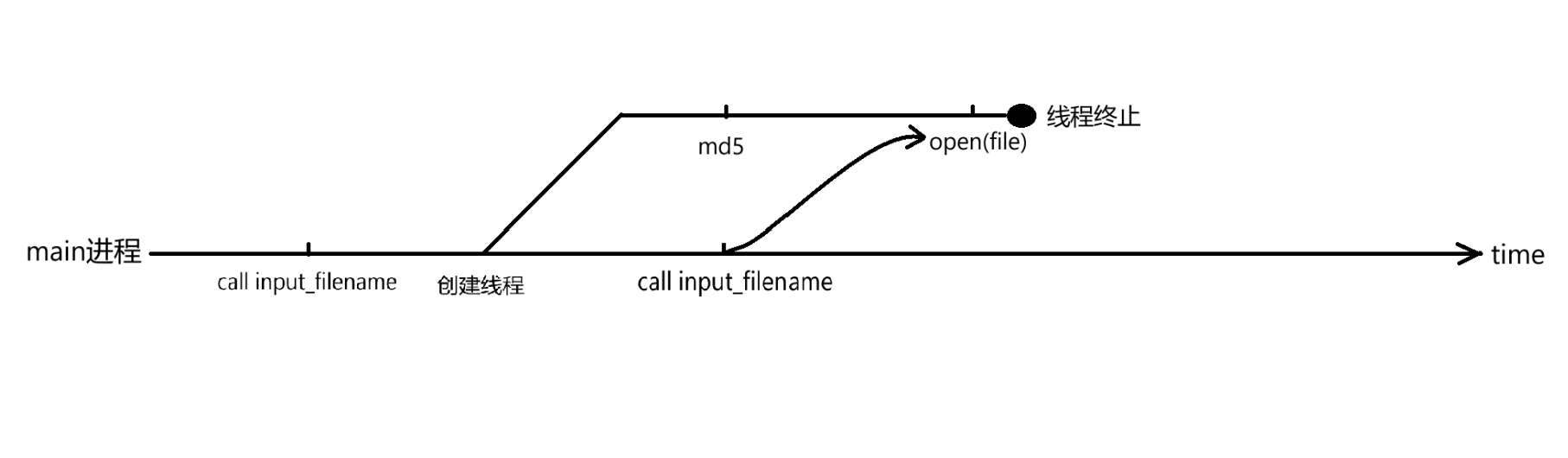
我们只需要在输入一个一个文件名后立马输入第二个文件名flag就有可能实现在open前替换filename为flag
然后通过格式化字符串将flag打印
EXP
1 | from pwn import * |
解码flag
1 | def hex_to_string(hex_list): |
0x01smallbox
程序逻辑很简单
1 | int __fastcall main(int argc, const char **argv, const char **envp) |
先fork,子进程进入死循环,父进程执行沙箱后任意代码执行
其中沙箱
1 | line CODE JT JF K |
只允许父进程进行ptrace调用
ptrace介绍
1 |
|
| 参数 | 含义 |
|---|---|
request |
请求类型 |
pid |
被调试进程的 PID |
addr |
地址参数(依赖于请求类型) |
data |
数据参数(依赖于请求类型) |
常见的请求宏
| 宏名 | 描述 |
|---|---|
PTRACE_TRACEME |
表示自己要被父进程调试(子进程调用) |
PTRACE_PEEKDATA/PTRACE_PEEKUSER |
读取数据或用户区(寄存器) |
PTRACE_POKEDATA/PTRACE_POKEUSER |
写入数据或用户区(寄存器) |
PTRACE_GETREGS/PTRACE_SETREGS |
获取或设置所有通用寄存器(x86、x86_64) |
PTRACE_CONT |
继续执行被暂停的子进程 |
PTRACE_SINGLESTEP |
单步执行 |
PTRACE_ATTACH |
附加到一个正在运行的进程(类似 GDB attach) |
PTRACE_DETACH |
从目标进程分离,目标继续运行 |
PTRACE_SYSCALL |
每次系统调用前暂停目标,常用于 syscall hook |
PTRACE_KILL |
杀死被调试进程 |
PTRACE_SEIZE |
非侵入式 attach,用于新型调试接口 |
PTRACE_INTERRUPT |
中断目标(常用于 SEIZE 模式) |
我们使用的gdb就是依赖于ptrace调用,我们在gdb中可以对被调试的进程进行内存写入,内存查看,寄存器修改等等操作,几乎可以控制子进程的所有行为
回到题目,我们看到子进程在fork后立马进入了while(1),并没有开启沙箱,所以思路很简单:父进程附加到子进程上,将shellcode注入子进程,后修改子进程的RIP修改为0xDEADC0DE000,最后脱离子进程,子进程便开始执行父进程注入的shellcode
EXP
1 | from pwn import * |
我们可以从栈上获得子进程的进程号,然后attach上去,注意attach需要相对比较长的时间
通常情况下可以使用wait调用等到附加成功,但本题只能调用ptrace,我们可以写一个loop强行等待到attach成功
然后就是常规的将shellcode写入子进程,最后PTRACE_DETACH脱离子进程
0x03ASTRAY
自定义的菜单题,实现了一个可以以usr和master身份管理一个记事本的系统
1 | int __fastcall __noreturn main(int argc, const char **argv, const char **envp) |
其中init中实现了对内容堆块的申请,初始化,并为每个堆块标记了权限
其中operate_chunk的结构为
1 | 00000000 usr_chunk struc ; (sizeof=0x18, mappedto_8) |
1 | __int64 init() |
chunk[0]被标记为0x10,chunk[1~9]为3,其余为2
1 | ssize_t user_operation() |
在usr操作中,可以进行的子操作有usr_write和usr_read
其中检查函数
1 | __int64 __fastcall check(unsigned int Id, const char *s, int a3) |
对usr_read无检查,usr_write会通过&操作检查权限是否符合3&1=1/2&1=0
所以usr_read只能写chunk[1~9]
然后根据操作字符串,映射对应的操作码
1 | int __fastcall permission_confirm(__int64 a1, const char *a2) |
将造作字符串转化为对应的操作码
1 | ssize_t __fastcall manager_operation(__int64 a1) |
manager_operation中提供了两类操作,分别是manager_write/read与manager_write_usr/manager_read_usr
check复用了usr中的check,仍然是对read操作无检查
对manager_write进行了堆块权限的检查
对manager_operate_usr是根据进行的最后一次usr操作的chunk确定,还会额外调用checkvisit进行检查
1 | _BOOL8 __fastcall checkvisit(int a1) |
要求进行操作的堆块进行的最后一次usr操作的操作码不能是4(正常来说,必须是能在usr态编辑的chunk才能保证操作码不为4)
由于这个系统对read的检查不够严格,我们可以随便read,其中最特殊的chunk便是chunk[0],拥有最特殊的权限0x10,
chunk[0]中也包含着堆地址与PIE偏移
我们先把exp.py的自定义函数写好
1 | from pwn import * |
先是manager_read(0),获得两个地址
1 | man_read(0) |
在manager_write_usr中,操作的堆地址便是从*((void* )(chunk[0])+1)中获得
如果我们可以控制chunk[0],便可以对任意地址进行单次0xff大小的写入
但是想要操作chunk[0],使用usr_write或manager_write是不行的,因为会有严格的权限检查
使用manager_write_usr,虽然不会进行权限检查,但是要求被操作的堆块在usr态被标记了非read操作
但是我们又无法使用usr_write为chunk[0]打上write操作码1
check检查最大的问题就是,完全没有考虑以usr态输入manager相关操作字符串会怎么样?
首先是可以通过check检查,因为如果以usr态进入且操作字符串不为usr_write就会返回1
在permission_confirm中,并不会检查身份,即使以usr身份进行manager操作,也会返回合法的操作码
也就是如果我们以usr身份对chunk[0]进行manager操作,不光不会报错,还可以为chunk[0]添加一个非4的操作码,这样我们就可以用manager_write_usr操作chunk[0]了
1 | def get_right(): |
1 | usr_write(10,b'a'*0x50) |
然后我们可以对任意地址进行写,但是我们只有一次机会,因为把chunk[0]修改后便无法再次直接使用manager_write_usr操作chunk[0]
我们无法使用manager_write操作chunk[0]是因为chunk[0]的权限太特殊了,是0x10
如果我们把chunk[0]的权限修改为0xf,那么manager_write便可以直接操作chunk[0]:配合manager_write_usr可以实现任意地址写;配合manager_read可以实现任意地址读
1 | man_write_usr(0,p64(0)+p64(heap+0x22d0)+p64(head+0x18)+p64(head+0x20)+p64(head+0x28)+p64(pie+0x4068)) |
对got表进行读,获得libc_base,从而获得environ地址
1 | man_write(0,p64(0)+p64(heap+0x22d0)+p64(head+0x18)+p64(head+0x20)+p64(head+0x28)+p64(pie+0x4020)) |
对environ进行读,获得stack地址
1 | stack=base+libc.sym.environ |
对manager_operat的返回地址进行写,通过ROP进行getshell
1 | man_write(0,p64(0)+p64(heap+0x22d0)+p64(head+0x18)+p64(head+0x20)+p64(head+0x28)+p64(stack-0x150)) |
实际操作中,不知道为什么远程的got表中地址和本地不一致,无法计算libc,转而使用IO指针,才得到libc_base
EXP
1 | from pwn import * |
0x04canutrytry
依旧菜单题
1 | void __fastcall __noreturn main(void *a1, char **a2, char **a3) |
init中把flag读入bss中,并开启沙箱,白名单留下open,read,write
1 | void init() |
IDA的反编译没有把异常处理部分展示出
menu处的异常处理为
1 | .text:0000000000401F19 ; catch(char const*) // owned by 401ED4 |
visit与leave的异常处理部分
1 | .text:0000000000401F7B ; catch(char const*) // owned by 401EEA |
其中visit用于创造堆块,编辑堆块,但是create把输入大小与malloc分为两个单独的步骤
且size会检查整形溢出,edit不会检查下标
1 | unsigned __int64 visit() |
在leave中,允许我们将一个chunk的内容复制到leave的栈中,并通过size检测是否栈溢出并抛出异常
c++异常处理
c++ 异常处理在抛出(throw)异常后,执行两个主要步骤:
1.栈展开(stack unwinding)
- 一旦抛出异常,程序会开始逐级退栈,调用每个函数的析构函数来清理资源(RAII)
- 栈帧会被逐个销毁,直到找到能处理异常的
catch语句 - 如果找不到,就会调用
std::terminate()
2.查找异常处理器(catch block)
- 异常对象的类型(如
std::runtime_error)会被用来比对每一层的异常处理表(这些表通常是编译器生成的结构体或元数据) - 一旦匹配成功,就跳转到对应的
catch块执行,继续正常执行
在 C++ 异常处理中,通过返回地址逆向查找异常处理器:
- 每个函数的返回地址(RIP)存在于栈帧中
- 栈展开时,会查看返回地址对应的代码段
- 根据地址查询异常表
.eh_frame,决定:- 是否有处理器
- 是否要执行析构器
- 是否要跳到下一个栈帧
也就是说,触发异常时根据返回地址确定异常抛出于哪个try代码块中,并查看处理器是否能处理此处异常
当我们在leave中栈溢出覆盖返回地址,但不改变返回地址,我们就可以调用leave相关异常处理函数
leave相关异常处理函数会提供给我们一个libc地址
同时我们覆盖rbp,也可以实现栈迁移,由于leave中
1 | if ( size_list[v5] > 16 ) |
中的exception为栈上变量,由rbp确定位置,我们还可以通过覆盖rbp为bss地址,在bss上写入0x4031D7(“stack overflow”的地址)
回到visit的edit部分,根据chunk_list进行负向溢出,可以写bss上存在的一个指针,同时要求对应的size_list必须存在
但是size_list为int数组;chunk_list为指针数组,二者单个元素的大小不同
如果我们能直接修改bss上的stdout指针,便可以在调用menu时触发IO将flag打印出来
但是我发现当chunk_list+idx==stdout时,size_list[idx]为0,且如果我们提前通过栈迁移将0x4031D7写入此时的size_list[idx],程序会因为栈过低在某一步抛出异常
既然没法修改stdout,我就先在bss上寻找一开始残留的可用地址
1 | 00:0000│ 0x405000 —▸ 0x404dd8 ◂— 1 |
我发现
6b:0358│ 0x405358 (std::cin+216) —▸ 0x4052d0 (std::cin+80) ◂— 0
中存放了一个更低地址的指针,如果我们写这个指针,能反过来覆盖0x405358中的内容,再次编辑便可以实现任意地址写,恰好我们得到了libc_base,那直接修改IO结构体便可以leak_flag
我尝试栈迁移将0x4031D7写入对应的size_list[idx]中,发现不会触发上次的问题
1 | from pwn import * |
栈迁移到bss+获得libc_base
1 | add(0x200) |
此时我们编辑-70,便可以将_IO_2_1stdout_写入0x405210
1 | ch(1) |
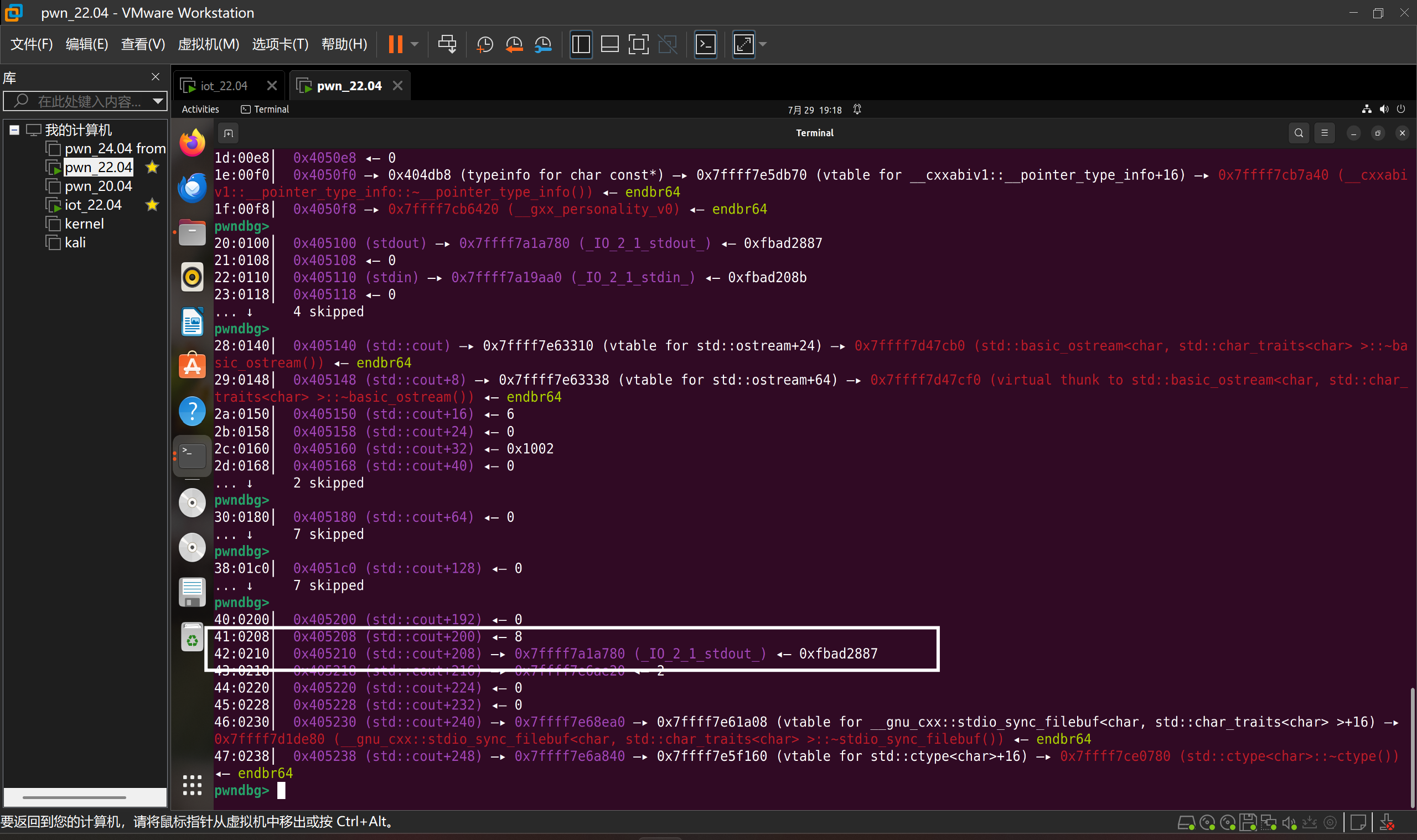
成功写入
再次编辑-70堆块,便是编辑IO结构体
1 | ch(1) |
此时main循环会回到menu,在menu中触发IO流,打印出flag
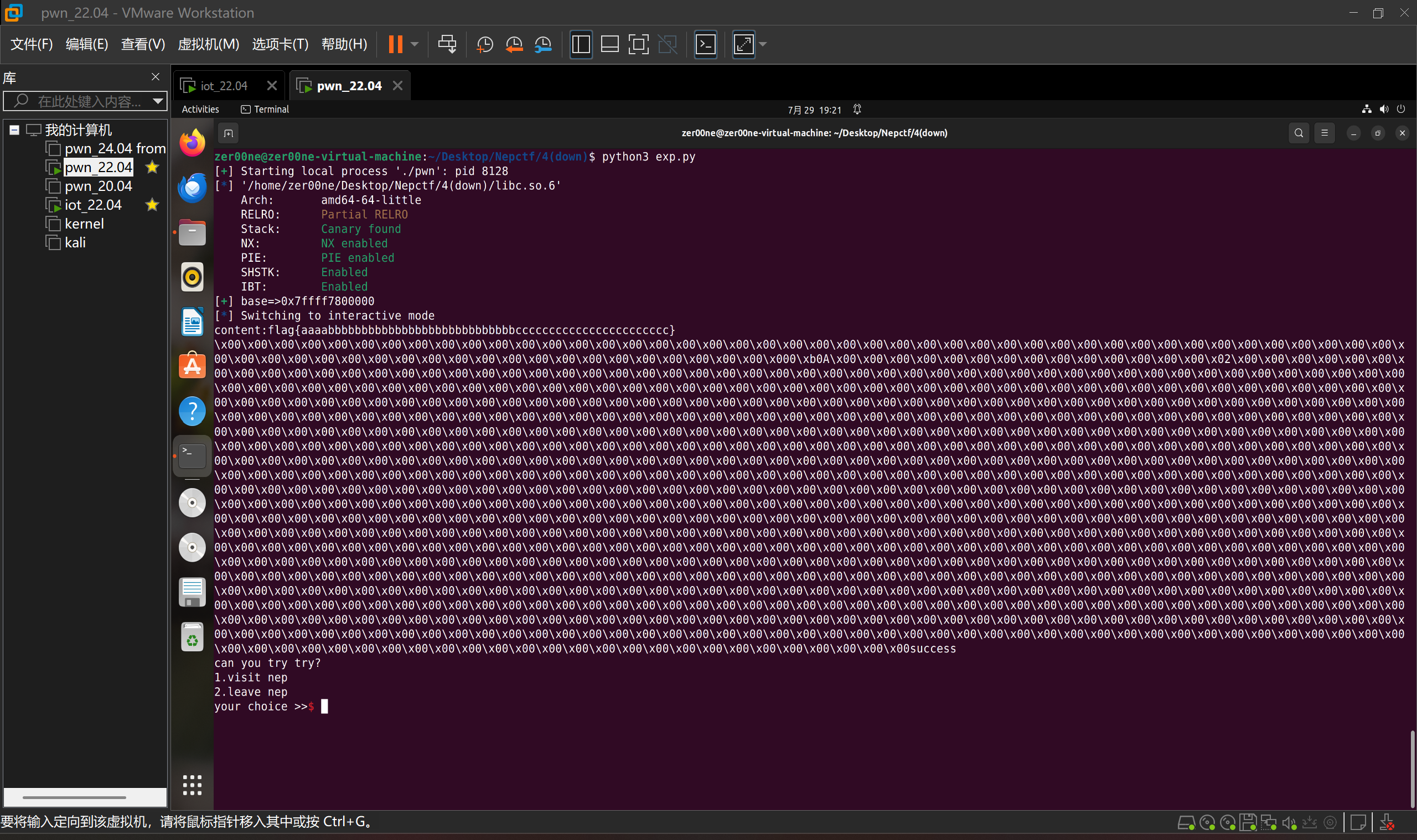
EXP
1 | from pwn import * |